
اژدهای گیمینگ 35 ساله شد
MSI به عنوان یکی از برندهای برتر گیمینگ، نامی مورد اعتماد در گیمینگ است و در طول 35 سال فعالیت خود، افتخارات بزرگی را از آن خود کرده است. در ادامه با داستان شنیدنی ام اس آی آشنا شوید.
نقد و بررسی کارتهای گرافیک سری 3000:
بعد از مدتها درز کردن شایعات مختلف و گمانهزنیها پیرامون کارتهای گرافیک سری ۳۰۰۰ انویدیا، سرانجام این کارتها رسما معرفی شدند و اطلاعات قطعی و دست اولی را در اختیار ما گذاشتند تا با امکانات و محدودهی تقریبی راندمان این مدلها نسبت به همردههای نسل قبلی بیشتر آشنا شویم. این اطلاعات شامل طراحی برد مدار چاپی (PCB) جدید، مصرف توان و مدلهای تعیین شده برای محصولاتی بود که قرار است در موج اولِ عرضهی نسل آمپر به بازار عرضه شوند. اولین محصولات همانطور که حتما در خبرهای قبلی خواندید، شامل GeForce RTX 3080 ،GeForce RTX 3090 و GeForce RTX 3070 میشوند که نمودارهایی مقایسهای هم از راندمان آنها در مقایسه با نسلهای قبلی نشان داده شد که نگاه کلی و نه آزمایشگاهی به مقولهی راندمانی که باید از مدلهای مذکور انتظار داشته باشیم را ارائه کردند.
مهمترین موضوع در مورد کارتهای گرافیک سری آمپر این است که فاصلهی ایجاد شدهی بین نسلی میان تورینگ و آمپر به گفتهی انویدیا، بیشترین میزانی است که تاکنون شاهد بودهایم. در گذشتهی نهچندان دور، یکی از بهترین ارتقاهای راندمانی را از نسل مکسول به پاسکال (از GTX 980 به GTX 1080) شاهد بودیم و اکنون احتمالا افزایشِ راندمان بیشتری را از مهاجرت از کارتهای سری RTX 20 به RTX 30 تجربه کنیم.
از نظر ابعاد هم کارتهای انویدیا بزرگترین اندازه در بین کارتهای گرافیکِ قبلی شرکت و حتی کارتهای شرکای تجاری دیگر یا AIB را دارند و در داخل کیس هم ۳ اسلات را برای RTX 3090 و ۲ اسلات را برای RTX 3080 و RTX 3070 اشغال میکنند. میزان مصرف توان هم در مجموع افزایش داشته و با وجود استفاده از فناوری ساخت ۸ نانومتری سامسونگ، باز هم به منبع تغذیه قدرتمندتری نسبت به نسل گذشته نیاز داریم. استفاده از یک منبع تغذیهی ٧۵۰ واتی برای مدلهای RTX 3090 و RTX 3080 و منبع تغذیهی ۶۵۰ واتی برای مدل RTX 3070 توسط انویدیا و سازندگانِ دیگر توصیه شده است.

همچنین انویدیا با طراحی خنک کنندهی جدید خود ادعا میکند که ۵۵ درصد جریان هوای بیشتری را هدایت میکند، ۳ برابر نویز کمتری دارد و ۳۰ درصد کارآمدتر از طراحیهای قبلی است. طبق معمول باید کارتهای جدید را تحت آزمون قرار داد تا صحت و سقم آمار اعلام شده تایید یا رد شود.
در مورد فنهای موجود در خنککننده هم دو فن وجود دارد که یک فن در قسمت عقب هوا را از جلوی کارت به سمت بالا میکشد و یک فن دیگر هوای گرم شده را از داخل کارت و از شیار پشت کیس به بیرون فشار میدهد. این طراحی به این معنی است که هوا در قسمت زیر GPU قرار میگیرد و از دو مسیر، یا از پشت کارت خارج میشود و یا اگر پردازنده خنککنندهی مستقل داشته باشد، به خنککنندهی CPU دمیده میشود. با در نظر گرفتن این تغییر طراحی، ممکن است خنککنندههای مدار بستهی مایع از این پس کارایی و راندمان بهتری نسبت به خنککنندههای برجی شکلِ بزرگ داخل کیس داشته باشند، چرا که دمیده شدنِ حرارت کارت گرافیک به برج خنککننده، باعث افزایش دمای محیطی و در نتیجه کاهش راندمان آن خواهد شد.

پیش از این گمانهزنیهای زیادی در مورد اینکه تراشههای Ampere بر اساس معماری ۷ نانومتری TSMC یا ۸ نانومتری سامسونگ ساخته میشوند در اینترنت منتشر میشد، اما سرانجام مشخص شد که انویدیا سامسونگ را به عنوان سازندهی اصلی و پروسهی ساخت ۸ نانومتری این شرکت را هم برای طراحی و تولید تراشههای گرافیکی خود برگزیده است. این انتخاب احتمالا به خاطر اشباع کامل خط تولید ۷ نانومتری TSMC با سفارشهای شرکت اپل و ایامدی بوده است. باید منتظر بود و دید که بازدهی خط تولید سامسونگ برای تراشههای ۸ نانومتری انویدیا جوابگوی نیاز بازار خواهد بود یا خیر.
مقایسهی مشخصات فنی
به گفتهی انویدیا معماری آمپر علاوه بر ارتقای بخش Shader برای واحدهای ترسیم سنتی یا Rasterization، به واحدهای ray tracing نسل دوم و واحدهای Tensor نسل سوم نیز مجهز شده است. در این جدول مشخصات فنی سه کارت گرافیک معرفی شده از معماری جدید آمپر را در برابر همتایان قبلیِ آنها از معماری تورینگ مشاهده میکنید:
| نام کارت گرافیکی | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 3080 | NVIDIA GeForce RTX 3070 | NVIDIA GeForce RTX 2070 SUPER | NVIDIA GeForce RTX 2080 SUPER | NVIDIA GeForce RTX 2080 Ti |
| معماری تراشه | Ampere | Ampere | Ampere | Turing | Turing | Turing |
| مدل تراشه | GA102-300 | GA102-200 | GA104-300 | TU104 | TU104 | TU102 |
| پروسهی ساخت | 8nm | 8nm | 8nm | 12nm FNN | 12nm FNN | 12nm FNN |
| تعداد ترانزیستورها | 28Billion | 28Billion | ? | 13.6Billion | 13.6Billion | 18.6Billion |
| هستههای CUDA | 10496 | 8704 | 5888 | 2560 | 3072 | 4352 |
| توان رهگیری پرتو | 69TFLOPs | 58TFLOPs | 40TFLOPs | 7Giga Rays/s | 8Giga Rays/s | 10Giga Rays/s |
| فرکانس پایه | 1395MHz | 1440MHz | 1500MHz | 1605MHz | 1650MHz | 1350MHz |
| فرکانس بوست | 1725MHz | 1710MHz | 1725MHz | 1770MHz | 1815MHz | 1545MHz |
| توان محاسباتی | 35.7TFLOPs | 29.7TFLOPs | 20.45TFLOPs | 9.1TFLOPs | 11.1TFLOPs | 13.4TFLOPs |
| ظرفیت حافظه | 24GB GDDR6X | 10GB GDDR6X | 8GB GDDR6 | 8GB GDDR6 | 8GB GDDR6 | 11GB GDDR6 |
| سرعت حافظه | 19.50Gbps | 19.00Gbps | 16.00Gbps | 14.00Gbps | 15.50Gbps | 14.00Gbps |
| رابط حافظه | 384bit | 320bit | 256bit | 256bit | 256bit | 352bit |
| پهنای باندِ حافظه | 936GB/s | 760GB/s | 512GB/s | 448GB/s | 496GB/s | 616GB/s |
| اتصالات برق | 12Pin | 12Pin | 8Pin | 8+6Pin | 8+8Pin | 8+8Pin |
| توان حرارتی | 350W | 320W | 220W | 215W | 250W | 260W |
| شروع قیمت | $1499US | $699US | $499US | $499US | $699US | $999US |
GeForce RTX 3090
هستهی GPU در این کارتِ غولپیکر، از تراشهی GA102 با تعداد ۱۰۴۹۶ واحد گرافیکی (CUDA Cores) تشکیل شده که ۸۲ واحد پردازشی مستقل (SM Units) در GPU را در برمیگیرد. همچنین حافظهی گرافیکی این کارت دارای عرض باند ۳۸۴ بیتی و ظرفیت بسیار بالای ۲۴ گیگابایتی است. این میزان حافظهی گرافیکی رکوردی جدید محسوب میشود و برای اولین بار است که استفاده از این حجم از حافظهی گرافیکی را در یک کارت گرافیک مخصوص بازی شاهد هستیم.
پهنای باند حافظه به لطف استفاده از GDDR6X برای اولین بار در یک کارت گرافیک گیمینگ، به ۹۳۶ گیگابایت بر ثانیه بالغ خواهد شد، سرعتی که قبل از این تنها در کارتهای سری تایتان و با استفاده از حافظههای HBM/HBM2 دستیافتنی بود. در هر حال استفاده از ۲۴ تراشهی یک گیگابایتی روی برد بر خلاف تصور قبلی به واقعیت بدل شد و طراحی مدارات را پیچیده کرد، چرا که تعداد فوقالعادهی ۲۴ تراشه در پشت و روی این برد برای فرآهم کردن ۲۴ گیگابایت حافظهی GDDR6X نصب میشود.

هنوز اطلاعات فنی و دیاگرامی رسمی از معماری واحدهای SM در آمپر منتشر نشده، اما بر طبق اعلام انویدیا، تعداد واحدهای سختافزاری RT در معماری آمپر دو برابرِ معماری تورینگ شده و با این پیشفرض، راندمان ray tracing یا رهگیری پرتو نیز تا سطح دو برابر بالاتر از نسل قبلی خواهد بود. همچنین تا جایی که مربوط به محاسبات اعشاری است، واحدهای FP32 در هر SM هم دو برابر افزایش داشته و RTX 3090 قادر است تا ۳۵ ترافلاپس محاسبات مبتنی بر FP32 را عرضه کند که در مقایسه با RTX 2080 Ti حدود ۲.۶ برابر بیشتر است و با استانداردهای فعلی هم رقمی بسیار شگفتانگیز و فوقالعاده است.
کارت Founders Edition جدید ساخت انویدیا برای تامینِ توان مورد نیاز، به کانکتور جدید ۱۲ پینی مجهز شده است، اما کارتهای سفارشی ساخت برندهای دیگر با ۲ یا ۳ کانکتور ۸ پینی مشاهده شدهاند و از کانکتور ۱۲ پینی استفاده نکردهاند. این موضوع نشان میدهد که مصرف توان در کارتهای پرچمدار جدید افزایش یافته، اما راهکارهای متفاوتی برای تامین این توانِ اضافه شده از سوی شرکتهای مختلف اتخاذ شده است. همچنین برخی سازندگان مثل ایسوس هم ترجیح میدهند به جای تامین توان ۷۵ واتی از اسلات PCI Express، تمام توان مورد نیاز کارت را مستقیما از طریق کابلهای برق PCIe و منبع تغذیه تامین کنند.
قیمت این کارت هم ۱۴۹۹ دلار تعیین شده که بسیار بالاتر از استاندارد کارتهای اختصاصی گیمینگ در بازار تجاری است و آن را در ردهی کارتهای گرانقیمت تایتان قرار میدهد. مشخصا این کارت پیش از هر اولویت دیگری، برای کسب عنوان قهرمانی و حفظ جایگاه برتر در رقابت با محصول رده بالای AMD با معماری RDNA 2 در آیندهای نزدیک هدفگذاری شده و لزوما برای استفادهی گیمرهای حرفهای و رفع نیازِ کنونی آنها در نظر گرفته نشده است.
GeForce RTX 3080
کارت گرافیک GeForce RTX 3080 اولین کارت گرافیکی بود که در رویداد اختصاصی انویدیا رونمایی شد و از آن به عنوان پرچمدار جدید یاد شد، محصولی که راندمانی بسیار بالاتر از پرچمدار نسل قبلی دارد و از همه مهمتر با قیمتی معقول به فروش خواهد رسید. کارت 3080 با قیمت پایهی ۶۹۹ دلاری برای کارت Founders Edition ساخت انویدیا، در تاریخ ۲۷ شهریورماه عرضه خواهد شد. این کارت ۱۰ گیگابایت حافظهی کاملا جدید GDDR6X ساخت شرکت مایکرون را در جوار GPU در بر دارد و توان محاسباتی آن برای FP32 روی واحدهای Shader یا سایهزن سنتی هم ۳۰.۵۸ ترافلاپس عنوان شده است. توان محاسباتی واحد رهگیری پرتو هم بر خلاف نسل تورینگ با ترافلاپس ارائه شده و میزان آن برای RTX 3080 برابر با ۵۸ ترافلاپس است. در آخر واحدهای هوش مصنوعی و یادگیری ماشینی Tensor هم ۲۳۸ ترافلاپس توان محاسباتی را در اختیار دارند.

کارت گرافیک RTX 3080 نیز از همان تراشهی GA102، اما با تعداد واحدهای پردازشی کمتر بهره خواهد برد. تعداد واحدهای پردازشی فعال CUDA در اینجا ۸۷۰۴ واحد است که نسبت به ۱۰۴۹۶ واحد در RTX 3090، به میزان ۱۷۹۲ واحد یا حدود ۱۸ درصد کمتر است. همچنین این محصول با گذرگاه ۳۲۰ بیتی به ۱۰ یا ۲۰ تراشهی یک گیگابایتی GDDR6X متصل خواهد شد. در نتیجه شاهد ۱۰ یا ۲۰ گیگابایت حافظهی پرسرعت گرافیکی برای RTX 3080 خواهیم بود که پهنای باندی برابر با ۷۶۰ گیگابایت بر ثانیه خواهد داشت. این پهنای باند هنوز هم از پهنای باند ۶۱۶ گیگابایت بر ثانیهایِ کارت RTX 2080 Ti به میزان ۱۴۴ گیگابایت بر ثانیه سریعتر است.
GeForce RTX 3070
سرانجام معرفی کوچکترین عضو فعلی کارتهای گرافیکی آمپر را داشتیم که کارت گرافیک قدرتمند و خوش قیمتِ RTX 3070 بر مبنای تراشهی GA104 و با عرض باند حافظهی ۲۵۶ بیتی خواهد بود. این کارت به ۸ تراشهی حافظهی GDDR6X متصل شده و بسته به ظرفیت هر تراشه، به ۸ یا ۱۶ گیگابایت حافظه مجهز خواهد شد. تعداد واحدهای پردازشی استفاده شده در این مدل ۵۸۸۸ واحد است که توان محاسباتی آنها در Shader-های سنتی ۲۰.۴۵ ترافلاپس اعلام شده است. توان پردازشی واحدهای رهگیری پرتو هم ۴۰ ترافلاپس و واحدهای Tensor برابر با ۱۶۳ ترافلاپس عنوان شده است. این محصول با مشخصات ذکر شده به گفتهی انویدیا، قدرتی بیشتر از RTX 2080 Ti دارد و قرار است با قیمت پایهی ۴۹۹ دلاری به فروش برسد.

این واقعیت که در انتهای سال ۲۰۲۰ میلادی، کارت گرافیکی به بازار عرضه شده که میتواند کارت گرافیک قدرتمند سال ۲۰۱۸ میلادی را با ۵۰۰ دلار قیمت پایینتر شکست دهد، خود به تنهایی نشانهی پیشرفت گستردهی بین نسلی در فناوری کارتهای گرافیکی انویدیا به حساب میآید. پیشرفتی که در نهایت مشتری نهایی و گیمرها از آن منتفع خواهند شد.
NVIDIA RTX IO
امروزه ذخیرهسازها با وجود پیشرفت زیاد و استفاده از SSD-های سریع، هنوز هم ضعیفترین قسمت رایانهها محسوب میشوند. سرعت SSD-های مدرن با بهره گیری از توانِ کامل گذرگاه PCIe در هر نسل افزایش مییابد و در PCIe نسل چهارم، سرعت این گذرگاه به ۶۴ گیگابیت بر ثانیه (۸ گیگابایت بر ثانیه) در دو جهت رسیده است. هم اینک شرکت ایامدی پلتفرم مبتنی بر PCIe 4.0 را عرضه کرده، اما اینتل فقط در پلتفرم نسل یازدهم موبایلی از آن استفاده کرده و انتظار میرود آن را همزمان با عرضهی پردازندههای نسل Rocket Lake، به کاربران رایانههای رومیزی نیز عرضه کند.
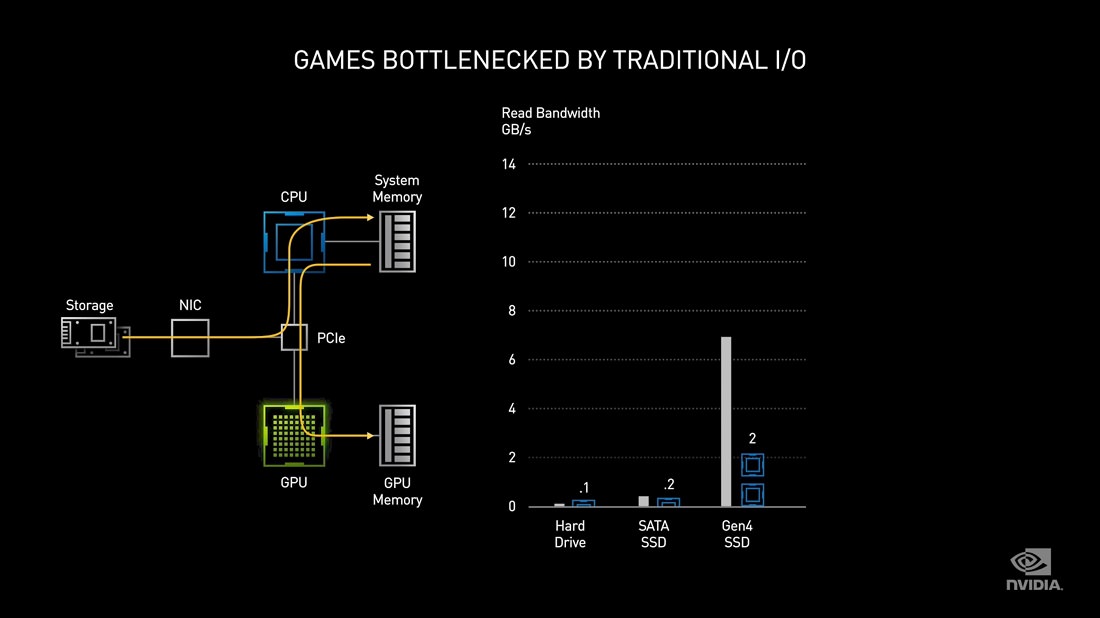
با اینکه افزایش پهنای باند ذخیرهساز امری مثبت تلقی میشود، اما پردازش اطلاعات باینری صفر و یک ذخیره شده روی بخش فیزیکی دیسکها هنوز بر عهدهی پردازندهی مرکزی یا CPU است. با افزایش پهنای باند ذخیرهسازها، بار پردازشیِ عملیات ورودی/خروجی یا I/O هم به همان نسبت روی پردازنده به تدریج افزایش پیدا میکند و به جایی میرسد که راندمان را تحت تاثیر قرار میدهد. مایکروسافت راه حل رابط برنامهنویسی DirectStorage را برای حل این معضل در نظر گرفته و انویدیا هم فناوری RTX IO را بر مبنای همین API ابداع کرده است.
انویدیا میگوید دادههای غیر فشرده حداکثر با سرعت ۷ گیگابایت بر ثانیه از یک SSD از نوع NVMe و روی گذرگاه PCIe 4.0 خوانده میشوند و برای پردازش در این سرعت به توان کاملِ دو هستهی پردازنده نیاز دارند. اما اگر همین اطلاعات بصورت فشرده شده و محتوایی مانند دادههای بازی باشند، به هزاران درخواست I/O و منابع متعددی نیاز است تا اطلاعات از حالت فشرده، به حداکثر ۱۴ گیگابایت بر ثانیه در حالت غیرِ فشرده تبدیل شوند. سربار ناشی از درخواستهای مضاعف I/O و توان مورد نیاز برای خواندن دادهها از داخل فایلهای متعدد و بارگذاری آنها در بافر کارت گرافیکی، توان پردازشی مورد نیاز در سمت پردازنده را به ۲۴ هسته افزایش میدهد. اینجا DirectStorage وارد عمل میشود و مسیری را برای دسترسی مستقیم به منابع مورد نیاز و برداشتن سربار پردازنده ایجاد میکند.
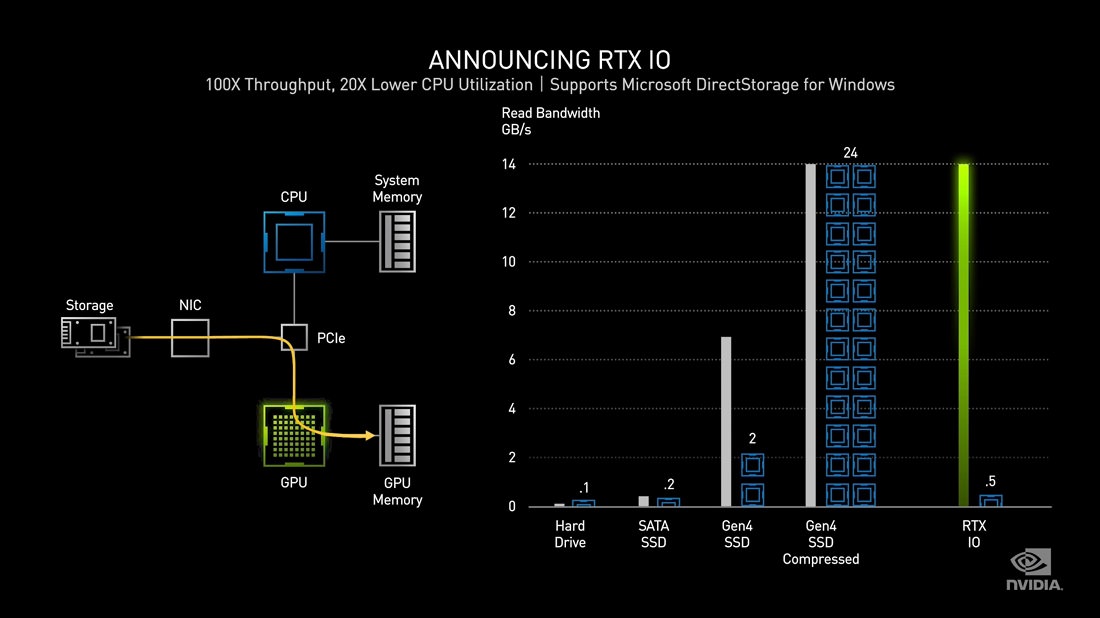
همچنین RTX IO به عنوان لایهی بیرونی DirectStorage که برای بازیها و معماری تراشههای گرافیکی انویدیا بهینه شده، غیر فشرده کردن دادههای فشرده شده را به صورت سختافزاری روی GPU انجام میدهد. انویدیا ادعا میکند که این فناوری تا ۲ برابر راندمان عملیات ورودی/خروجی با ذخیرساز را افزایش میدهد و در عین حال نیاز به استفاده از هستههای متعدد پردازنده برای مدیریت خواندن و نوشتن را از میان برمیدارد.
البته نیاز است که بازیها برای استفاده از قابلیت DirectStorage بهینه شوند. با توجه به اینکه این API اکنون هم در کنسول ایکس باکس سری ایکس پیاده سازی شده، بازیهایی که برای این کنسول عرضه شده و به پیسی پورت شوند، احتمالا از این فناوری برخوردار خواهند بود. همچنین پشتیبانی RTX IO باید به صورت مجزا برای هر بازی در درایور گرافیک انویدیا تعبیه شود.
این فناوری روی تمام کارتهای گرافیکی RTX از نسل تورینگ و آمپر کار خواهد کرد و با بروز رسانی API مربوطه در نسخهی سال ۲۰۲۱ ویندوز 10، میتوان انتظار داشت که استفاده از این قابلیت از نیمهی دوم سال آینده عملیاتی شود. در ضمن مایکروسافت میگوید این قابلیت به ملزوماتی نیاز دارد که باعث میشود تمامِ درایوهای M.2 و NVMe برای بهره بردن از آن مناسب نباشند و احتمالا فقط مدلهای پرسرعتتر برای این قابلیت چراغ سبز خواهند گرفت.
Nvidia Reflex
فناوری دیگری که همزمان با معرفی کارتهای گرافیک جدید معرفی شد، به گیمرهای آنلاین وعدهی بهرهمندی از کاهش تاخیر و افزایش سرعت پاسخگویی سیستم در هنگام بازی را میدهد. به گفتهی انویدیا این قابلیت خود مشتمل بر برخی نوآوریها در تراشهی گرافیکی، تکنیک G-Sync و برخی دیگر قابلیتهای نرمافزاری است که سنجش و کاهش تاخیر سیستم در هنگام اجرای بازیهای رقابتی را ممکن میسازند. کاهش تاخیر سیستم برای گیمرهای آنلاین امری حیاتی است که به پیسی و نمایشگر اجازهی واکنش سریعتر در برابر دستورات ورودیِ کاربر از طریق ماوس و صفحه کلید را میدهد و دقت در عکسالعملها و شلیکها را افزایش میدهد.
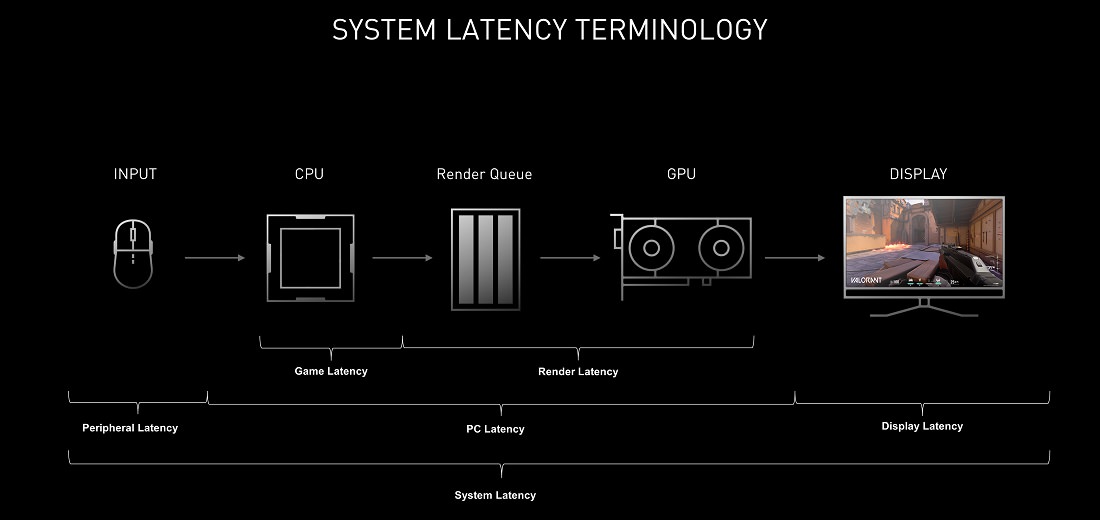
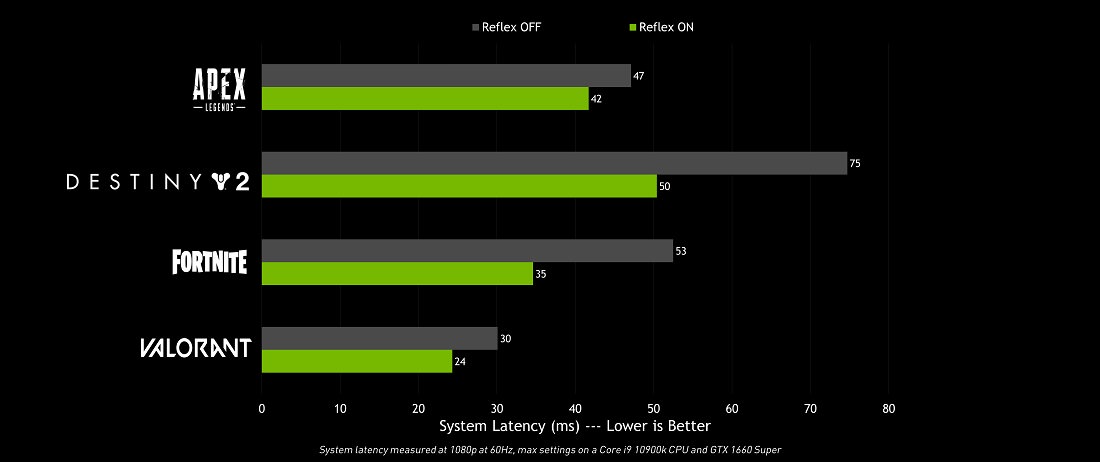
این قابلیت مختص نسل جدید نیست و روی کارتهای گرافیکی GTX 900 و بالاتر قابل اجرا خواهد بود و از نسخهی بعدی درایورهای انویدیا در اواخر شهریور در دسترس قرار خواهد گرفت. همچنین طبق آزمونهای انویدیا، این قابلیت در برخی از معروفترین بازیهای رقابتی به این شکل تاثیرگذار بوده است:
جمع بندی
به جز مشخصات فنی و محدودهی راندمانیِ کارتهای گرافیکی جدید، اطلاعات دیگری در مورد قابلیتهای بالقوهی افزایش کارایی واحدهای RT و Tensor در تراشههای نسل Ampere هم منتشر شده که مبتنی بر استفادههای گستردهتر از امکانات این نسل است، امکاناتی که در بخش تولید محتوا و سهولت دسترسی به کیفیت بصری بالاتر و همینطور کاهش زمان و هزینهی اجرای پروژههای گرافیکی تاکید دارند. از سوی دیگر افزایش خیره کننده در راندمان تکنیک رهگیری پرتو و همینطور واحدهای هوش مصنوعی و ML باعث شده که اجرای بسیاری از بازیها با استفادهی کامل از هر دوی این تکنیکها و نرخ فریم بسیار بالاتر و روانتر برای اولین بار میسر شود و گلایههای قبلی در مورد راندمان ray tracing در بازیها در نسل تورینگ به دست فراموشی سپرده شود. همچنین انویدیا بستهی نرم افزاری DLSS 2.1 با امکانات بیشتر نسبت به DLSS 2.0 را هم معرفی کرده که برخی امکانات جدید مثل قابلیت ارتقای کیفی تصویر در رزولوشن 8K برای کارت فوق قدرتمندی مانند RTX 3090 هم فرآهم میشود.

مقالهی مرتبط
فناوری DLSS در نسخهی ابتدایی چیزی بیش از یک تکنیک Image Sharpening معمولی به نظر نمیرسید، اما تحول بینظیر ایجاد شده در DLSS 2.0 و اجرا روی هستههای Tensor تراشههای RTX باعث شد که یکی از بینقصترین تکنیکهای ارتقای تصویری و upscaling را در بازیهای ویدیوئی شاهد باشیم. در واقع DLSS 2.0 بسیار از جزئیاتی را که با اِعمال تکنیک TAA روی صحنه محو میشوند یا از بین میروند را دوباره به تصاویر برمیگرداند و در بسیاری موارد کیفیتی حتی بالاتر از اجرای بازی در رزولوشن Native را ارائه میکند. بازی Death Stranding یکی از بهترین نمونههای پیادهسازی تکنیک DLSS 2.0 بعد از بازی Control ساختهی رمدی است که میتواند الگوی بیمانندی برای مایکروسافت و سونی برای پیادهسازی قابلیتهای مشابه بر مبنای هوش مصنوعی در کنسولهایشان باشد.
فناوری DirectStorage در کنار RTX IO، عقب افتادن پیسی در برابر کنسولهای نسل جدید در حذف یا کاهش صفحات بارگذاری بازیها را جبران خواهند کرد
یکی از مورد انتظارترین فناوریهای مدنظر برای پیسیهای مخصوص بازی، عرضهی قابلیتی با توانایی جبران ضعف سختافزار در بارگذاری و انتقال دادهها از ذخیرهسازها بود که به لطف همکاری انویدیا و مایکروسافت به زودی محقق خواهد شد و نقطه ضعف اصلی پلتفرم پیسی نسبت به کنسولهای نسل جدید که هر دو از SSD-های پرسرعت و واحدهای شتابدهندهی سختافزاری برای غیرفشردهسازی دادههای بازی استفاده میکنند، در میان مدت برطرف خواهد شد. فناوری DirectStorage در کنار RTX IO، استفادهی واقعی و بدون گلوگاه از سرعت بالای SSD برای حذف یا کوتاه کردن صفحات لودینگ را در بازیهای پیسی فرآهم خواهد کرد و استریم بیوقفه و بدون تاخیر بافتهای کیفیت بالا را مانند آنچه که در نمایشهای سونی از بازیهای پلی استیشن 5 شاهد بودیم محقق میکند.
بسیار مشتاق هستیم ببینیم که پس از رفع محدودیتهای انویدیا، کارتهای گرافیکی نمونه در دست ژورنالیستهای دنیای فناوری و سختافزار چه نتایجی را در بنچمارکها رقم خواهند زد و این محصولات جدید تا چه میزان در بازار خرده فروشی قابلیت پاسخگویی به تقاضای خریداران را خواهند داشت. همچنین واکنش ایامدی با عرضهی احتمالا قریب الوقوع کارتهای گرافیک مبتنی بر معماری RDNA 2 هم بسیار جالب توجه و تعیینکننده خواهد بود و احتمالا روزهای داغی را در این عرصه پیشِ رو خواهیم داشت.
